《C++ Premier, 5th Edition》读书总结

- 🪛 一本 CPP 入门级别的书籍, 在有 ObjC/C 的基础上进行快速总结.
- 📒 涵盖 C++ Primer 中文版(第 5 版) 中 1-16 章知识点.
1. 准备
开始阅读本书前, 参考CMake官方教程以及modern-cmake 整理标准的 CMake 工程仓库。规范项目源代码文件/单元测试目录/公共头文件目录/以来库安装目录. 上传至 cpp-playground。
2. 语法基础
2.1 类型&常量
基础类型与 C 相差无异: char/int/bool/float 外加一个 void; 对于不同的 primitive type, 引入更进一步的 sub_type 支持不同尺寸变量:

老生常谈 type conversion:
- bool 到非 bool,true 为 1, false 为 0.
- 非 bool 算数类型, 非 0 为 true, 0 为 false.
- 大尺寸数到小尺寸数转换, 小尺寸数取模. (在不做声明的情况下会存在报错).
- 小尺寸数到大尺寸数转换,值不会丢失.
String & Char:
- Char 使用 ‘’
- String 使用 ““, Char 可在 String 中通过
\外接 Dec/Hex 进制表示字符. -
使用以下前缀标记默认字符大小:
e.g.L’a’, u8”Hi”. etc.
以下初始化写法均为合法:
int units_sold = 0;
int units_sold = {0};
int units_sold {0};
int units_sold(0);
注意: CPP 中会强调初始化与赋值的区别
- **初始化是对未赋予值的对象赋予值, **
- 赋值的含义是已经对初始化的对象的值进行抹去,然后重新给一个新值
引用
使用&d进行表达. 主要是对变量/对象进行重命名. 对于同一个变量来说, 可以使用多个 reference 对其进行关联: (这里的引用主要讲解左值引用).
int x = 10;
// ref is a reference to x.
int &ref = x;
// Value of x is now changed to 20
ref = 20;
cout << "x = " << x << '\n';
// Value of x is now changed to 30
x = 30;
cout << "ref = " << ref << '\n';
指针
使用*d进行表达. 用法与 ObjC /C 语法类似:
int ival = 42;
int *p = &ival;
跟 C/OC 一样那么指针的指针可以这么套娃 🪆 写:
int ival = 1024;
int *pi = &ival; // 指向int的指针
int **ppi = π // 指针的指针
对于对象指针来说, 可通过箭头函数调用:
// my class
class MyClass {
public:
void func() { // 函数体 }
};
// 指针函数调用
MyClass* obj = new MyClass(); // 创建对象指针
obj->func(); // 使用箭头运算符调用对象的函数
delete obj; // 释放内存
指针的四种可能状态 (C/ObjC 同样适用):
- 指向一个对象
- 指向临近对象占用空间的下一个位置
- 空指针
- 无效指针
常量定义
使用const, 常量默认 scope 为当前文件. 定义全局常量时,方式与 OC 相同:
// xxx.cc
// declare & initialize in .cc file
extern const int buffSize = 1024;
// xxx.hpp
// define const in header
extern const int bufSize;
因为上文提到了 Reference 以及 Pointer, 这里着重强调一下 Const Reference/Pointer 的一些特性
- 指向 const 的 reference 不可被修改,会触发编译器报错.
- 指向 const 的指针本身也必须为 const,否则会触发编译器报错. (但常量类型的指针可指向非常量对象)
处理数据类型
- 继续老生常谈,使用 typedef 对类型设置 alias
- 使用 auto 进行类型自动推导
- 使用 decltype 类型指示符
int i = 42, *p = &i, &r = i;
decltype(r + 0) b; // correct, b as int type
decltype(*p) c; // incorrect c is int&, must be initialized
decltype((r + 0)) d; // incorrect d as int&, must be initialized
常量表达式
AKA: constexpr 在编译阶段对表达式求值,进一步减少运行时计算成本:
constexpr int sum(int x, int y) {
return x + y;
}
int main() {
constexpr int a = 5;
constexpr int b = 7;
constexpr int result = sum(a, b);
return 0;
}
2.2 字符串 / 向量 / 数组
String 表述可遍尝字符序列,Vector 则存放某种给定对象的可变长序列
字符串
初始化方式总结, 其核心皆为拷贝
string s1 = "";
string s2(s1);
string s3 = s1;
string s3("value");
string s3 = "value";
string s4(n, 'c');
String 中的字符操作提供了常用函数:

在 C++11 起, 遍历 String 也与大多语言一样,可直接在 for 语句中完成
string test_07_16_iterate_str() {
string s = "Hello World!";
for (auto &c : s) {
c = toupper(c);
}
cout << "s: " << s << endl;
return s;
}
矢量
描述对象的集合,其中所有对象的类型都相同. Vector 的本质属于一个类模版(Class Template), 与其对应的还存在函数模版(Function Template), 与 String 类似 支持多种创建方式。

// template function for printing the vector
template <typename S>
ostream& operator<<(ostream& os,
const vector<S>& vector)
{
// Printing all the elements
// using <<
for (auto element : vector) {
os << element << " ";
}
return os;
}
void test_07_16_vector() {
vector<int> v1;
vector<int> v2(v1);
vector<int> v3 = v1;
vector<int> v4 = {1, 2, 3, 4, 5};
v1.push_back(1);
v1.push_back(2);
cout << v1 << endl;
cout << v2 << endl;
}
Vector 常见函数以及使用方法:
- empty()
- size()
- push_back()
- 操作符:
==, !=, <, >, >=, <= - vector<${TYPE}>::size_type - 每个元素的大小
- vector<${TYPE}>::iterator - 迭代器,用于删除元素
讲到了迭代器,下面就再重点介绍一下 Vector 的迭代器用法.
void test_07_16_iterator_vector() {
vector<int> v1 = {1, 2, 3, 4, 5};
// v1.end() points to the position
// right after the last element
for (auto it = v1.begin(); it != v1.end(); ++it) {
*it = *it * 2;
}
cout << v1 << endl;
}
迭代器的算数运算符可总结为
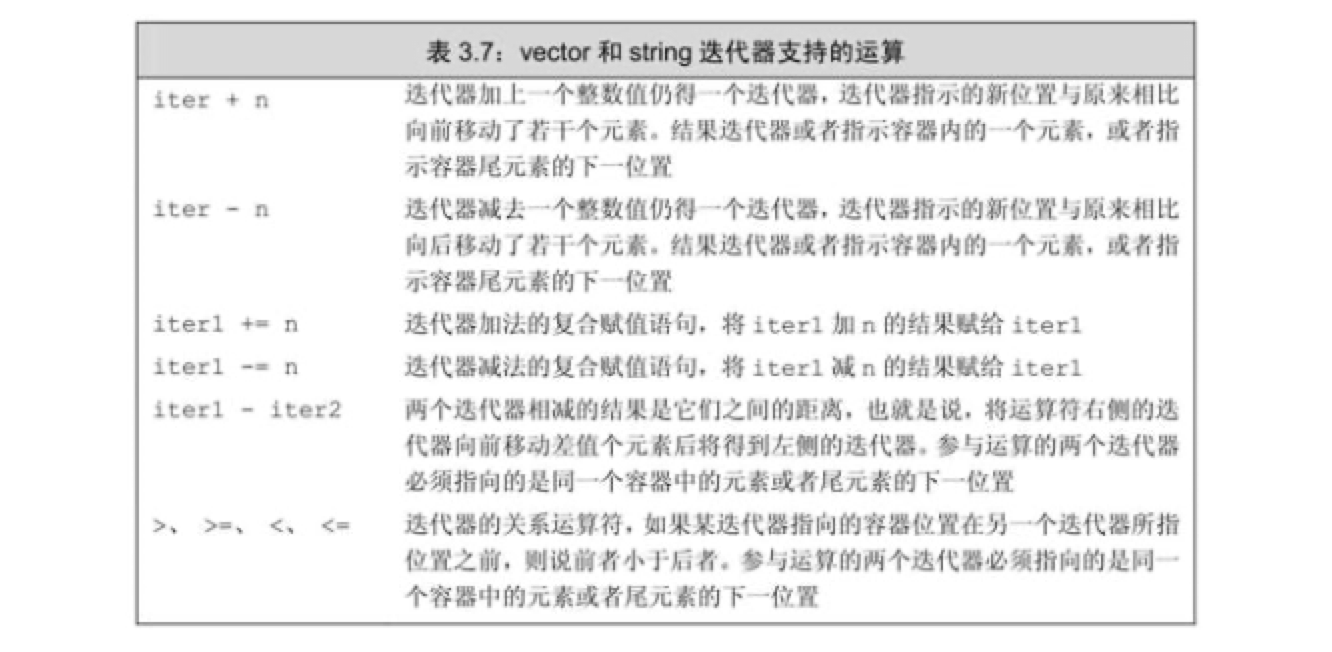
迭代器常见操作如下: 注意这里迭代器的++, * 操作并非针对指针,而是迭代器自己提供的定义操作符:
std::vector<int> vec = {1, 2, 3, 4, 5};
for (std::vector<int>::iterator it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << std::endl;
}
数组
与矢量不同:
- 数组不可进行尺寸调整.
- 数组不可被拷贝赋值.
- 不支持 auto 类型的推断.
- 数组不支持元素引用(Reference): ❌ int &refs[10] = / _ ? _/ , 但数组层面支持引用 ✅ int (&arrRef)[10] = arr.
数组如果完成声明后,未对其中的元素进行赋值,那么其中的元素均为默认缺省值
void test_07_16_array() {
unsigned scores[11] = {};
unsigned grade;
for (unsigned element : scores) {
cout << element << " ";
}
}
在 CPP 中,指针与数组有非常紧密的联系,就如即将介绍的:
string nums[] = {"one", "two", "three"};
string *p = &nums[0]; // point to the first element in array
string *p1 = nums; // same as above, here p and p1 is the same
使用数组的时候编译器一般会把它转换成指针; vector/string 支持的迭代器运算,数组指针全都支持.
遍历数组也可使用迭代器:
int ia[] = {1, 2, 3, 4, 5};
int *beg = begin(ia);
int *last = end(ia);
谨慎对待关于字符串使用:strlen/strcmp/strcat/strcpy 以及常见的 cout 等操作都需要字符串以空字符(‘\0’)结尾 不然会导致无法预测的后果
多维数组
本质上其实就是数组的数组,比如:
int ia[3][4] = {
{0, 1, 2, 3},
{4, 5, 6, 7},
{8, 9, 10, 11}
}
也可以优化为(个人认为比较影响可读性):
int ia[3][4] = {
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
}
在 C++11 开始,由于 for (xx : xx) 的写法会得到遍历元素的指针(因为 row 不是引用类型)。因此对一个多维数组的遍历时常需要如下操作:
// p 指向第一层数组元素,为第一层数组元素的指针.
for (auto p= ia; p != ia + 3; ++p) {
// 因为*p 本身反馈第二层数组,
// 因此q指向4个整数数组的首元素地址指针.
for (auto q = *p; q != *p + 4; +=q) {
cout << *q << ' ';
}
cout << endl;
}
同样如果使用标准库的 begin 以及 end 函数,上述的遍历也可写为:
// p 指向ia 的第一个数组
for (auto p = begin(ia); p != end(ia); ++p) {
// q 指向内层数组的首个元素
for (auto q = begin(*p); q != end(*q); ++q) {
cout << *q << ' ';
}
}
2.3 类声明与实现
与 C/ObjC 类似,CPP 允许在头文件中进行类声明,在具体的.CPP 文件中进行实现。比如下列中的:
// TestClass07.hpp
#include <string>
class TestClass07 {
public:
TestClass07();
TestClass07(std::string name);
~TestClass07();
std::string hello();
private:
std::string name;
};
// TestClass07.cpp
#include <string>
#include <iostream>
#include "TestClass07.hpp"
using namespace std;
TestClass07::TestClass07() {
cout << "TestClass07 constructor called." << endl;
}
TestClass07::TestClass07(std::string name) {
this->name = name;
cout << "TestClass07 constructor called with name: " << name << endl;
}
TestClass07::~TestClass07() {
cout << "TestClass07 destructor called." << endl;
}
string TestClass07::hello() {
return "Hello, " +this-> name + "!";
}
2.4 表达式 & 语句
表达式
老生常谈
- 一元运算符: +,- (BOOL 不参与一元运算)
- 二元运算符:*,/,%,+,-
- 递增/递减 ++/–
- 指针访问成员: -> , 非指针访问成员 .
- 条件运算符: xxxx ? xxx : xxx
-
位运算符: ~, «, », &, , ^
关于类型转换,隐式转换无需多言,与 C/ObjC 保持一致. 这里着重讲解一下显式转换:
- static_cast: 任何具有明确定义的类型转换,只要不包含底层 const 都可使用。也可以使用 static_cast 来找回 void * 指针所指向的值.
- dynamic_cast: 常用于 CPP 基类虚函数相关的 BaseClass 与 SubClass 的上下切换, 参考链接说明。
- const_cast:对常量对象转换成非常量对象的行为,如果 const_cast 对应执行的对象本身不是一个常量,那么这么做是合法的。
const int a = 10;
int* p = const_cast<int*>(&a);
*p = 20; // Now, a is 20
- reinterpret_cast:绕过编译器检查,强行将一个类型转换为另一个类型。
语句
这部分对应 Chapter 5 的内容, 只针对 CPP 的语言特性做一部分 基本语句:
- 一行一句,
;表示结束. - for / while / if / switch / do while.
- goto 跳转.
Try 语句块: 与 java 风格的 try catch 类似, 支持多层 catch. 在不同的 catch 段中捕获不同类型的异常,在发生异常并捕获后,需要及时清理并释放 try block 中的对象,因此需要保证程序的异常安全. 在本书的后部分也提到了相关提升异常安全的一些技巧. 也可单独阅读这篇文章了解部分技巧。
2.5 函数
函数发生调用时,参数对原对传入值进行拷贝。 引用拷贝引用,非引用对自身对象进行拷贝。 CPP 还提供了尾置返回类型(Trailing Return Type). 来简化函数表达
// 一个函数声明的两种写法
int(*func(int i))[10];
auto func(int i) -> int(*)[10];
默认参数 在 C++中,你可以在函数声明或定义时为参数提供默认值。这样,如果在调用函数时没有提供该参数的值,那么就会使用默认值。以下是一个简单的例子:
void myFunction(int a, int b = 10) {
// Function body
}
函数重载
与其他语言一样,CPP 支持函数重载, 注意,函数重载取决于行参(formal parameters), 而不由返回类型所决定.
Record lookup(const Account&);
Record lookup(const Phone&);
Record lookup(const Name&);
函数指针
函数的本质是指针, 因此可以声明函数指针类型的变量,并在运行时进行赋值
// 比较两个string 对象的长度
bool lengthCompare(const string &, const string &);
// pf 指向一个函数,该函数的参数为两个const string的引用
bool (*pf)(const string &, constr string &);
// 可进行以下赋值
pf = lengthCompare;
函数指针在进行 declare 后默认值为 nullptr, 任何尝试对 nullptr 进行调用的行为都会导致 runtime exception.
注意: C++ 函数中存在静态变量 (此处与 ObjC/C 类似) 注意: 行参传递支持 正常参数创建(拷贝赋值) | 引用传递 | 指针传递
2.6 类
在深入讨论类特性的时候,可以快速对比一下 CPP 中 class 与 struct 定义类的区别。 一般在 CPP 中如果所有类的成员是 public 时, 可使用 struct。反之如果成员时 private 的,那么可直接使用 class。
友元
友元(Friend)可以访问其他类中的非公有成员。友元必须在类定义的内部. 友元的声明仅仅制定了访问的权限,而非通常意义上的函数声明。如果我们希望类的用户能够调用某个友元函数,那么必须在友元声明之外再专门对函数做一次声明。友元可以是函数,也可以是其他的类。
class Screen {
friend class WindowMgr;
}
内联
CPP 支持内联(inline) 优化,列子如下:
inline Screen &Screen::set(char c) {
// operation
// 返回this 指针所指Screen 值,
return *this;
}
上述对象中,因为是返回自身值,因此要用&Screen 表示返回引用,否则返回的 Screen 将会被复制一份. 延伸阅读 inline v.s. constexpr
构造函数
建议在构造函数中初始化各字段的值, 并且如果成员初始化存在依赖顺序,建议构造函数初始值的顺序与成员声明顺序保持一致。
class X {
int i;
int j;
public:
X(int val): i(val), j(i) {}
};
对于简单的类, 可以使用默认构造函数,不过一旦涉及到复合类型/内置类型成员变量时,则需要自己定义构造函数. 不然创建对象的时候将得到为定义的值.
在 3.5 中进一步讨论拷贝/赋值运算前简单对拷贝/赋值运算做一下区分:
拷贝:通常在创建新对象时发生,涉及到拷贝构造函数。拷贝构造函数用于创建一个新的对象作为现有对象的副本 j(i) 赋值:
j = i
聚合类
聚合类(Aggregate Class) 使得用户可以直接访问其成员,并且具有特殊的初始化语法形式。 当一个类满足如下条件时,我们说它是聚合类
- 所有成员为 public
- 没有定义任何构造函数
- 没有类内初始值
- 没有 Base 类,没有虚函数
例子:
Data val = { "Anna", 1024 };
静态成员
类的静态函数/变量可在类内部或者外部声明,在外部声明时,不可使用 static 关键字。static 成员可为常量,不过常量定义必须使用 constexpr。
class Account {
public:
static double rate() { return interestRate; }
static void rate(double);
private:
static constexpr int period = 30; // period 是常量表达式
double daily_tbl[period];
}
3. CPP 特性
3.1 IO
在第一部分语法基础已经整理了大部分 IO 库设施:istream/ostream/cin/cout/cerr,这里进一步拓展其他的 IO 类型. 诸如 iostream/sstream/fstream, 分别对应读写流基本类型, 读写文件类型, 读写内存 string 对象类型.
流对象参考:

诸多 stream 对象统一遵循集成规则,比如 istream 的接口适用于 ifstream, istringstream. (同 cin). IO 对象无法被拷贝。 由于 IO 对象本身是读写异常的高发区,因此 IO 对象提供一些基本的状态: iostate/badbit/failbit, etc
缓冲管理
文本串可立即打印,也可能被操作系统缓冲区域保存。 通过缓冲,可将多次操作系统输出合并成单一系统写操作提升操作性能。 可使用 unitbuf 操作符在每次操作后强制刷新缓冲区:
cout << unitbuf;
“当调试一个已经崩溃的程序时,需要确认那些已经输出的数据已经刷新了。否则可能存在程序崩溃后缓冲区没有刷新,数据输出被挂起但没有打印”
文件输入输出
ifstream (给定文件读数据) / ofstream(给定文件写数据) / fstream(给定文件读写数据) 参考链接
3.2 顺序容器
顺序容器与关联容器为 CPP 中的两种核心容器类型. 本章节介绍顺序容器. CPP 自带顺序容器包含:
- vector :可变大小数组,支持快速随机访问。 在尾部之外的位置插入或者删除元素比较慢 。
- deque : 双端队列,支持快速随机访问,头尾部插入删除速度快。
- list : 双向链表,可支持双向顺序访问,支持任意位置插入 删除.
- forward_list: 单向链表,其他操作类似 list
- array : 固定大小数组,只能提供访问不提供修改
- string : 类似于 vector,不过主要用于操作 char.
关于容器选择,提供简单的分类法则说明:
- 默认使用 vector
- 对于大量小元素的储存,避免 list/forward_list
- 如果需要使用随机元素,使用 vector/deque
通用操作
通用容器操作一览

反向容器额外成员

这里着重对比一下 SWAP 以及 ASSIGN 操作的区别
- Array 本身从右向左赋值, 赋值时发生拷贝,赋值后迭代器失效
- Swap 本身对两个容器中的元素内容进行交换。元素本身并不会发生拷贝删除或者插入操作。因此在 Swap 之后迭代器依然有效。
运算关系符
每个容器类型都支持相等运算符,除了无需关联容器外的所有容器都支持关系运算符 ++ , != 除了无序关联容器外的所有容器都支持关系运算符 (>, <, <=, >=). 运算符对象必须为相同类型相同元素类型。
容器操作
向容器中添加元素和从容器中删除元素的操作可能会使指向元素的指针,引用,迭代器失效。推荐的做法是在 for 循环中,每次取最新的.end 迭代器指针.
while (begin != v.end()) {
++begin;
beding = v.insert(begin, 42); // 插入新值
++begin;
}
矢量的增长
为了支持快速随机访问,vector 将元素连续存储——每个元素紧挨着前一个元素存储。通常情况下,我们不必关心一个标准库类型是如何实现的,而只需关心它如何使用。然而,对于 vector 和 string,其部分实现渗透到了接口中。
假定容器中元素是连续存储的,且容器的大小是可变的,考虑向 vector 或 string 中添加元素会发生什么:如果没有空间容纳新元素,容器不可能简单地将它添加到内存中其他位置——因为元素必须连续存储。容器必须分配新的内存空间来保存已有元素和新元素,将已有元素从旧位置移动到新空间中,然后添加新元素,释放旧存储空间。常见容器大小管理操作有:

额外字符串操作
出了标准的构建器,容器函数等等,字符串本身也提供了更多便捷的函数:
容器适配器
Stack / Queue / Priority_Queue 基于容器的基础上,进一步封装的模型. 每个适配器都定义两个构造函数:默认构造函数创建一个空对象,接受一个容器的构造函数拷贝该容器来初始化适配器
// 在vector 上实现的空栈
stack<string, vector<string>> str_stk;
// str_stk2 在vector 上实现,初始化时保存对svec的拷贝
stack<string, vector<string>> str_stk2(svec);
默认情况下,stack/queue 基于 deque 实现,priority_queue 在 vector 上实现。也可在创建一个适配器时将一个命名的顺序容器作为第二个类型参数, 来重载默认容器类型。
3.3 范型算法
由于容器本身只定义了有限的操作,更多的运算函数通过标准库提供的范型算法(Generic Algorithm)所支撑。本书里介绍了一些范型算法:
- find
- accumulate
- copy
- replace
- sort
范型算法的本质其实是类模版。比如那上述的accumulate函数举例,其实质是对 iterator 模版的调用:
template< class InputIt, class T >
T accumulate(
InputIt first,
InputIt last,
T init
);
其中 iterator 属于类模版,被各类容器所套用:
template<
class Category,
class T,
class Distance = std::ptrdiff_t,
class Pointer = T*,
class Reference = T&
> struct iterator;
细节可以看这篇文章: C++中的范型与模版
定制操作
标准库的范型算法也支持一系列的定制操作, 感觉这里有些函数式编程的味道:
// 比较函数, 用来按照长度排序单词
bool isShorter(const string &s1, const string &s2) {
return s1.size() < s2.size();
}
// 按长度由短至长排序words
sort(words.begin(), words.end(), isShorter);
也可更近一步, 使用 CPP 中的 lambda:
// lambda 模版
[capture list](parameter list) -> return type {function body}
- lambda 中忽略括号已经参数列表等同于一个空参数列表。
- 如果忽略返回类型,则也将自动根据 return 语句对返回类型进行自动推导。
使用迭代器后, 上述 sort 函数可重写为:
// lambda 初探
stable_sort(
words.begin,
words.end,
[](const string &a, const string &b) {
return a.size() < b.size();
}
)
这里还没有谈到如何使用方括号, 在 lambda 正则表达式中, 方括号用于对表达式中多次使用的上下文信息进行捕捉。当向一个函数传递一个 lambda 时,同时定义了一个新类型和该类型的一个对象:传递的参数就是此编译器生成的类类型的未命名对象, 捕获参数为实际上存储在创建的未命名对象的内部。
// 获取一个迭代器,指向第一个满足size()>=sz的元素
auto wc = find_if(
words.begin(),
words.end(),
[sz](const string &a) {
return a.size() >= sz;
}
)
Lambda 捕获参数形式参考下表:

迭代器深入
除了容器自带的迭代器以外, 标准库在头文件 iterator 中还定义了额外的几个迭代器. 诸如 insert iterator/ stream iterator/ reverse iterator/ move iterator. 可根据链接自行阅读
3.4 关联容器
“来吧宝贝,又是一个容器的话题”
基本概念
与顺序容器不同,关联容器的元素访问通过关键字来进行. 关联容器类型为 map&set

一个经典的例子:
// string 到size_t的空map
map<string, size_t> word_count;
set<string> exclude = {"The", "But", "And", "Or"}
string word;
while (cin >> word) {
// 只统计不在exclude中间的词
if (exclude.find(word) == exclude.end())
++word_count[word];
}
关联容器对关键字要求能够提供 Comparable 相关的操作符( < ,=, >) 来对元素进行比较. 在 set 以及 map 需要进行自定义数据支持时, 可在 map, set 的尖括号中设定 compare 函数:
bool compareIsbn(const Sales_data &lhs, const &Sales_data &rhs) {
return lhs.isbn() < rhs.isbn;
}
multiset<Sales_data, decltype(compareIsbn)*>bookstore(compareIsbn);
Pair 类型
嗯 其他语言里的 Pair 用法类似:
pair<string, string> anon {"james", "joyce"};
cout << anon.first << endl;
修改
分下面四种修改场景讨论 (场景 1) 修改 Map: insert(或 emplace)返回的值依赖于容器类型和参数。对于不包含重复关键字的容器,添加单一元素的 insert 和 emplace 版本返回一个 pair,告诉我们插入操作是否成功。pair 的 first 成员是一个迭代器,指向具有给定关键字的元素;second 成员是一个 bool 值,指出元素是插入成功还是已经存在于容器中。如果关键字已在容器中,则 insert 什么事情也不做,且返回值中的 bool 部分为 false。如果关键字不存在,元素被插入容器中,且 bool 值为 true。
map<string, size_t> word_count;
string word;
while (cin >> word) {
// 插入一个元素,关键字等于word,值为1
// 若word已在word_count中,insert什么也不会做
auto ret = word_count.insert({word, 1});
if (!ret.second) {
++ret.first->second;
}
}
(场景 2) 修改 Multiset/Multimap: insert 一定会成功插入一个元素,并返回指向新元素的迭代器. (场景 3) 删除: 支持如图所示三种方式的删除

(场景 4) 下标操作:
- c[k] 返回关键字为 k 的元素,如果 k 不在 c 中,缇娜家一个关键字为 k 的元素,对其值进行初始化。
- c.at(k) 访问关键字为 k 的元素,带参数检查,如果不在,则抛出 out_of_range 异常。
TODO:// 待提供更多 map 使用的代码例子
3.5 内存 &拷贝控制
动态内存
到目前为止,我们编写的程序中所使用的对象都有着严格定义的生存期。全局对象在程序启动时分配,在程序结束时销毁。对于局部自动对象,当我们进入其定义所在的程序块时被创建,在离开块时销毁。局部 static 对象在第一次使用前分配,在程序结束时销毁。现在来看看动态对象。
‘指针’
CPP 提供三种智能指针管理动态对象,
- 传统的动态内存通过new 创建,通过delete 进行回收。 delete 是很危险的操作,对于一个非 new 分配的内存或者将 new 出的指针释放多次,行为都是未定义的。
- 而智能指针可以自动释放所指向的对象 (比如说进行 reset 操作)
- shared_ptr: 允许多个指针指向同一个对象
- unique_ptr: 独占所指对象
- weak_ptr: (弱引用) 指向 shared_ptr
智能指针的共有操作:

分别看看几种指针的操作方式:
类型: share_ptr:

// 参考上图中的操作方式
// 也可写为
// auto p1 = make_shared<int>(42);
shared_ptr<string> p1 = make_shared<int>(42);
if (p1 && p1->empty()) {
*p1 = "hi";
}
// 也可以显式的通过new 创建智能指针
shared_ptr<int>(new int(20));
类型: unique_ptr:
 一个 unique_ptr“拥有”它所指向的对象。与 shared_ptr 不同,某个时刻只能有一个 unique_ptr 指向一个给定对象。当 unique_ptr 被销毁时,它所指向的对象也被销毁 - 因此 unique_ptr 不支持普通的赋值以及拷贝操作.
一个 unique_ptr“拥有”它所指向的对象。与 shared_ptr 不同,某个时刻只能有一个 unique_ptr 指向一个给定对象。当 unique_ptr 被销毁时,它所指向的对象也被销毁 - 因此 unique_ptr 不支持普通的赋值以及拷贝操作.
注意: release() 操作并不会对内部管理的指针进行回收,只是“放弃控制权”,因此在 release 之后需要单独调用一次 delete(p) 操作
类型: weak_ptr: 顾名思义, 弱指针指向 shared_ptr, 但不会改变 shared_ptr 的引用计数。
 范例代码:
范例代码:
auto p = make_shared<int>(60);
weak_ptr<int> wp(p);
// lock 返回shared pt, 保证在调用链路中不被回收
if (shared_ptr<int> np = wp.lock()) {
}
‘数组’
除了动态指针外, 也支持动态分配/回收数组:
- 可通过 new / delete 的方式
typedef int arrT[42]; // arrT 为42个数组的类型别名
int *p = new arrT; // 分配一个42个数组; p 指向第一个元素
delete [] p; // 回收第一个
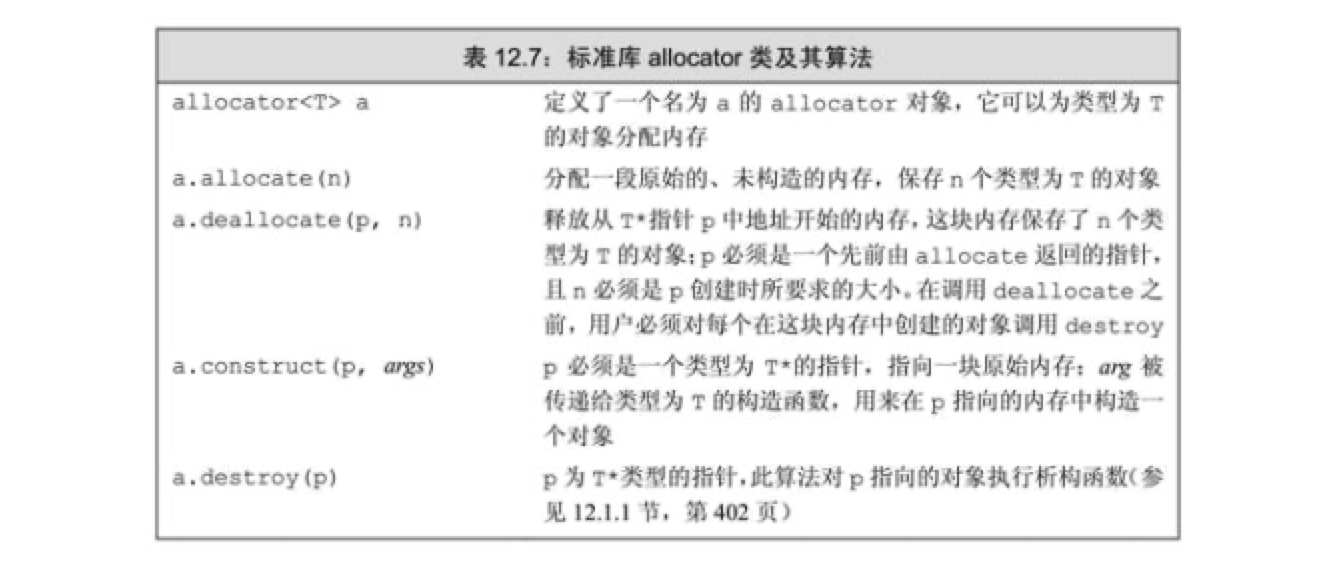
- allocator: 由于 new 在灵活性上的局限,它将内存分配与对象构造绑定在一起。 因此如果需要将内存分配与对象构造分离的话,可以使用 allocator。 对于每一个完成构造的指针,需要使用 destroy 进行操作。
allocator<string> alloc;
auto const p = alloc.allocate(n);
auto q = p;
alloc.construct(q++, "hi"); // now *q is "hi"
allocator 的常见函数参考:
拷贝控制
这部分主要讲解对象拷贝/赋值/移动/销毁时会做什么。主要是通过特殊的成员函数控制相关操作, 包含: 拷贝构造函数/移动构造函数/拷贝赋值运算符/移动赋值运算符/析构函数。
“当定义一个类时,我们显式或隐式的制定在此类型中的对象拷贝,移动,赋值,销毁操作”
拷贝构造函数
如果一个构造函数第一个参数为自身类型引用,切任何额外函数都存在默认值。 则当前构造函数为拷贝构造函数。在当前类未定义拷贝构造函数的情况下,编译器会自动生成。
class Sales_data {
public:
Sales_data(const Sales_data&);
private:
std::string bookNo;
int units_sold = 0;
}
// 外部实现
Sales_data::Sales_data(cibsr Sales_data &orig):
bookNo(orig.bookNo),
units_sold(orig.units_sold) { }
在拷贝构造过程中,对类类型成员,会使用拷贝构造函数来进行拷贝。 内置类型成员涉及直接拷贝。
赋值运算
与类控制对象初始化一样,类也可控制对象如何赋值,与拷贝构造函数类似,编译器会自动为类生成对应的拷贝复制运算符(synthesized copy-assigned operator).
// 等同于Sales拷贝赋值运算
Sales_data&
Sales_data::operator=(const Sales_data &rhs)
{
bookNo = rhs.bookNo;
units_sold = rhs.units_sold;
revenue = rhs.revenue;
return *this;
}
析构函数
在析构函数中,首先执行函数体,然后销毁成员。成员按照初始化顺序的逆顺序进行销毁。析构函数调用的时机包含:
- 对象作为对象离开作用域
- 当对象作为其他对象的成员,其归属对象被销毁时被销毁
- 容器被销毁
- 智能指针/动态分配销毁
class Sales_data {
public:
// 成员会被自动销毁
~Sales_data() { }
}
三/五法则
“如果一个类需要自定义析构函数,那么大概率它也需要自定义拷贝赋值运算以及拷贝构造函数”
阻止拷贝
虽然大多数类应该定义(而且通常也的确定义了)拷贝构造函数和拷贝赋值运算符,但对某些类来说,这些操作没有合理的意义。在此情况下,定义类时必须采用某种机制阻止拷贝或赋值。(比如说 iostream)
struct NoDtor {
NoDtor() = default; // 使用合成默认构造函数
NoDtor(const NoDtor&) = delete; // 表示不希望支持拷贝
~NoDtor() = delete; // 进制销毁NoDtor 类型对象.
}
对于拷贝构造函数以及拷贝复制运算符来说,可以通过设置其为 private 来组织拷贝。 为了进一步组织友元以及成员函数进行拷贝,在此不定义 private 的拷贝构造函数以及拷贝复制运算符。
常见技巧
(Case 1) 定义行为像值的类 假设当前存在类 HasStr, 内部包含一个 int 以及一个 string 指针,那么在拷贝赋值时,默认赋值的是指针的值,而不是具体指针指向的内容,如果希望 HasPtr 在赋值拷贝时,每个 string 成员都有自己的一份拷贝,那么需要:
- 定义一个拷贝构造函数 完成 string 的拷贝,而不是拷贝指针
- 定义一个析构函数来释放 string
- 定义一个拷贝赋值运算符来释放对象当前 string
class HasPtr {
public:
HasPtr(const std::string &s = std::string()):
ps(new std::string(s)), i(0) { }
// 对ps指向的string,每个HasPtr对象都有自己的拷贝
HasPtr(const HasPtr &p):
ps(new std::string(*p.ps)), i(p.i) { }
HasPtr& HasPtr::operator=(const HasPtr &rhs);
~HasPtr() { delete ps; }
}
HasPtr& HasPtr::operator=(const HasPtr &rhs)
{
auto newp = new string(*rhs.ps);
delete ps;
ps = newp;
i = rhs.i;
return *this;
}
(Case 2) 定义行为像指针的类 同理,当 HasPtr 需要作为指针类在赋值场景下传递时,实现如下
class HasPtr {
public:
HasPtr(const std::string &s = std::string()):
ps(new std::string(s)), i(0), use(new std::size_t(1)) { }
// 拷贝三个数据成员,并递增计数器
HasPtr(const HasPtr &p):
ps(new std::string(*p.ps)), i(p.i), use(p.use) { ++*use; }
HasPtr& operator=(const HasPtr&);
~HasPtr;
}
HasPtr::~HasPtr() {
if (--*use == 0) {
delete ps;
delete use;
}
}
HasPtr& HasPtr::operator=(const HasPtr &rhs) {
++*rhs.use;
if (--*use == 0) {
delete ps;
delete use;
}
ps = rhs.ps;
i = rhs.i;
use = rhs.use;
return *this;
}
(Case 3) 交换操作 阅读这篇文章: How C++ Swap Works, 其实质上是基于 std::move 操作. (Case 4) 动态内存管理类 我们在 StrVec 类中使用类似的策略。我们将使用一个 allocator 来获得原始内存。由于 allocator 分配的内存是未构造的,我们将在需要添加新元素时用 allocator 的 construct 成员在原始内存中创建对象。类似的,当我们需要删除一个元素时,我们将使用 destroy 成员来销毁元素。每个 StrVec 有三个指针成员指向其元素所使用的内存:
- elements,指向分配的内存中的首元素
- first_free,指向最后一个实际元素之后的位置
- cap,指向分配的内存末尾之后的位置
原文中整理完毕的代码段如下:
#ifndef STRVEC_H
#define STRVEC_H
#include <iostream>
#include <memory>
#include <utility>
// simplified implementation of the memory allocation strategy for a vector-like class
class StrVec {
public:
// copy control members
StrVec():
elements(0), first_free(0), cap(0) { }
StrVec(const StrVec&); // copy constructor
StrVec &operator=(const StrVec&); // copy assignment
~StrVec(); // destructor
// additional constructor
StrVec(const std::string*, const std::string*);
void push_back(const std::string&); // copy the element
// add elements
size_t size() const { return first_free - elements; }
size_t capacity() const { return cap - elements; }
// iterator interface
std::string *begin() const { return elements; }
std::string *end() const { return first_free; }
// operator functions covered in chapter 14
std::string& operator[](std::size_t n)
{ return elements[n]; }
const std::string& operator[](std::size_t n) const
{ return elements[n]; }
private:
static std::allocator<std::string> alloc; // allocates the elements
// utility functions:
// used by members that add elements to the StrVec
void chk_n_alloc()
{ if (size() == capacity()) reallocate(); }
// used by the copy constructor, assignment operator, and destructor
std::pair<std::string*, std::string*> alloc_n_copy
(const std::string*, const std::string*);
void free(); // destroy the elements and free the space
void reallocate(); // get more space and copy the existing elements
std::string *elements; // pointer to the first element in the array
std::string *first_free; // pointer to the first free element in the array
std::string *cap; // pointer to one past the end of the array
};
#include <algorithm>
inline
StrVec::~StrVec() { free(); }
inline
std::pair<std::string*, std::string*>
StrVec::alloc_n_copy(const std::string *b, const std::string *e)
{
// allocate space to hold as many elements as are in the range
std::string *data = alloc.allocate(e - b);
// initialize and return a pair constructed from data and
// the value returned by uninitialized_copy
return std::make_pair(data, uninitialized_copy(b, e, data));
}
inline
StrVec::StrVec(const StrVec &s)
{
// call alloc_n_copy to allocate exactly as many elements as in s
std::pair<std::string*, std::string*> newdata =
alloc_n_copy(s.begin(), s.end());
elements = newdata.first;
first_free = cap = newdata.second;
}
inline
void StrVec::free()
{
// may not pass deallocate a 0 pointer; if elements is 0, there's no work to do
if (elements) {
// destroy the old elements in reverse order
for (std::string *p = first_free; p != elements; /* empty */)
alloc.destroy(--p);
alloc.deallocate(elements, cap - elements);
}
}
inline
StrVec &StrVec::operator=(const StrVec &rhs)
{
// call alloc_n_copy to allocate exactly as many elements as in rhs
std::pair<std::string*, std::string*> data =
alloc_n_copy(rhs.begin(), rhs.end());
free();
elements = data.first;
first_free = cap = data.second;
return *this;
}
inline
void StrVec::reallocate()
{
// we'll allocate space for twice as many elements as the current size
size_t newcapacity = size() ? 2 * size() : 1;
// allocate new memory
std::string *newdata = alloc.allocate(newcapacity);
// copy the data from the old memory to the new
std::string *dest = newdata; // points to the next free position in the new array
std::string *elem = elements; // points to the next element in the old array
for (size_t i = 0; i != size(); ++i)
alloc.construct(dest++, *elem++);
free(); // free the old space once we've moved the elements
// update our data structure to point to the new elements
elements = newdata;
first_free = dest;
cap = elements + newcapacity;
}
inline
StrVec::StrVec(const std::string *b, const std::string *e)
{
// call alloc_n_copy to allocate exactly as many elements as in il
std::pair<std::string*, std::string*> newdata = alloc_n_copy(b, e);
elements = newdata.first;
first_free = cap = newdata.second;
}
inline
void StrVec::push_back(const std::string& s)
{
chk_n_alloc(); // ensure that there is room for another element
// construct a copy of s in the element to which first_free points
alloc.construct(first_free++, s);
}
#endif
移动构造函数(C++11 新特性)
在新版本 C++的实现中,部分标准库类提供了移动构造函数的机制,支持直接将入参中的值迁移到当前对象中,而非拷贝. 并保证在被移动的对象在移动发生后依然是一个有效的并且可析构的状态。对对象调用std::move 的直接后果其也是调用其对象本身的移动构造函数。
_“标准库容器,String, Shared_ptr 类既支持移动也支持拷贝” _
为了支持新类型的移动操作,新标准引入了新的引用类型: 右值引用(rvalue reference)。所谓右值引用就是必须绑定到右侧的引用。 它有一个重要的性质: 只能绑定到一个将要销毁的对象,因此我们可以自由的将一个右值引用的资源自由的“移动”到另一个对象中。 左值跟右值的例子可以参考如下代码:
int &&rr1 = 42; // correct, 42 为右值引用,(运算结果)
int &&rr2 = rr1; // wrong, rr1 为左值, (变量为左值,毕竟变量离开作用域时才会被销毁)
int &&rr3 = std::move(rr1); // ok "std::move 可接受左值对象,并且显式的将它转换成为右值."
那么接下来正式介绍移动构造函数与移动赋值运算符
StrVec::StrVec(StrVec &&s) noexcept:
elements(s.elements), first_free(s.first_free), cap(s.cap) {
s.element = s.first_free = s.cap = nullptr;
}
注意: 拷贝与移动赋值/构建运算的关系
- 定义了一个移动构造函数或移动赋值运算符的类必须也定义自己的拷贝操作。否则,这些成员默认地被定义为删除的。
- 如果一个类有拷贝构造函数但未定义移动构造函数,此时不会自动合成移动构造函数. 那么此类只支持被拷贝,即便是调用 move 也是如此,只会发生拷贝而不是移动。
- 如果一个成员函数同时提供拷贝和移动版本,那么它也能从中受益。根据入参类型的不同选择使用拷贝模式还是移动模式。
- 请注意,是否真正调用移动构造函数或移动赋值运算符,取决于类是否提供了这些函数,以及编译器的优化策略。在某些情况下,编译器可能会选择使用复制构造函数或复制赋值运算符,即使移动版本是可用的。这被称为复制搬移(copy elision)。
移动赋值运算符(C++11 新特性)
移动赋值运算符执行与移动构造函数相同的工作, 使用一个右值引用作为参数. 它与移动赋值构建函数调用时机的区别在于:
- 移动构造函数: 当你创建一个新对象并用一个临时对象(右值)初始化它时,会调用移动构造函数。
String s1("Hello");
String s2 = std::move(s1); // Move constructor is called
- 移动赋值运算符: 当你有一个已存在的对象,并且你用一个临时对象赋值给它时,会调用移动赋值运算符。
String s1("Hello");
String s2;
s2 = std::move(s1); // Move assignment operator is called
实际场景中移动赋值运算符的 🌰:
class String {
char* data;
size_t len;
public:
// Move assignment operator
// 移动操作通常不会抛出任何异常, 当便携一个不抛出异常的移动操作时,
// 我们应该将此事通知给标准库.
String& operator=(String&& other) noexcept {
if (this != &other) {
delete[] data; // Free existing resource
// Steal resources from other
data = other.data;
len = other.len;
// Reset other
other.data = nullptr;
other.len = 0;
}
return *this;
}
// Other members...
};
延伸阅读
- 左值(lvalue)
- 能够用&取地址的表达式是左值表达式
- 右值(prvalue)
- 本身就是赤裸裸的,纯粹的字面值,比如 3,false;
- 求职结果相当于字面值或者为不具名的临时对象。
- 将亡值(xvalue)一种即将过期的右值对象, 比如说:
std::move(s1);返回的就是一个将亡值. 并进一步被相关的移动构建函数函数或者移动赋值运算符消费.- 返回右值引用的函数调用表达式
- 转换为右值引用的转换函数调用表达式
- 如何理解“将亡”: 在 C++11 中,我们用左值去初始化一个对象或为一个已有对象赋值时,会调用拷贝构造函数或拷贝赋值运算符来拷贝资源(所谓资源,就是指 new 出来的东西),而当我们用一个右值引用来赋值时,赋值之后它也将马上销毁. 因此可理解为“将亡”.
3.6 运算符重载
✨ CPP 支持重载已有的运算符,无权发明新的运算符。

4. OOP
4.1 面向对象设计
C++ 中的 OOP 围绕“继承/抽象/动态绑定(多态)” 三点进行阐述.
- 继承成通过基类暴露虚函数,由子类实现并覆盖相关函数而来继承。 子类可以选择不 override,此时子类可以直接使用基类实现的虚函数。
- 而动态绑定的意思是,基类可以参与到日常函数调用中,具体调用的函数值由基类背后运行时中的实际类型来决定 (这里其实就是多态)。
类型转换:
- upcasting:把子类转换为基类是安全的
Derived derivedObj;
Base* basePtr = &derivedObj;
- downcasting: 把基类转换为子类, 则需要使用 dynamic_cast 做运行时转换,跳过编译时检查.
#include <iostream>
class Base {
public:
virtual void print() {
std::cout << "This is the base class" << std::endl;
}
};
class Derived : public Base {
public:
void print() override {
std::cout << "This is the derived class" << std::endl;
}
};
int main() {
Base* basePtr = new Derived(); // 基类指针指向派生类对象
// 使用 dynamic_cast 进行向下转型
Derived* derivedPtr = dynamic_cast<Derived*>(basePtr);
if (derivedPtr) {
// 转型成功,可以访问派生类的成员和函数
derivedPtr->print();
} else {
// 转型失败,基类对象不是派生类的对象
std::cout << "Cannot convert from Base to Derived" << std::endl;
}
delete basePtr;
return 0;
}
纯虚函数
在 C++中,可以通过在基类中的函数声明后面加上 “= 0” 来将其声明为纯虚函数。下面是一个示例:
class Base {
public:
virtual void pureVirtualFunction() = 0;
};
含有纯虚函数的类为抽象基类。抽象基类负责定义接口, 而后续其他类可以覆盖接口,抽像基类不可以被直接创建。
final&override
老生常谈, final 用于表示函数不再支持被覆盖,而 override 则说明当前函数是通过继承虚函数而来。
访问控制
三个访问控制权限,private/protected/public. 默认权限为 private. 派生类的友元只能访问派生类中自己的受保护成员,无法访问基类中的受保护成员。即,友元的关系不能够继承。
继承构造函数
这里很像 kotlin 的写法,哦, 应该说反了 🐶
class Base {
public:
Base(int x) {
// 构造函数逻辑
}
};
class Derived : public Base {
public:
Derived(int x, int y) : Base(x) {
// 派生类构造函数的逻辑
}
};
继承拷贝控制, 移动赋值成员
类似集成构造函数,派生类赋值运算符以及拷贝构造需要为其基类部分的成员赋值:
- 拷贝构造函数
class Derived : public Base {
public:
Derived(const Derived& other) : Base(other), derived_member(other.derived_member) {
// Copy construct other members...
}
// ...
};
- 拷贝复制运算符
class Derived : public Base {
public:
Derived& operator=(const Derived& other) {
if (this != &other) {
Base::operator=(other);
derived_member = other.derived_member;
// Copy other members...
}
return *this;
}
// ...
};
- 移动赋值
class Derived : public Base {
public:
Derived& operator=(Derived&& other) noexcept {
if (this != &other) {
Base::operator=(std::move(other));
derived_member = std::move(other.derived_member);
// Move other members...
}
return *this;
}
// ...
};
容器储存
当派生于同一个基类的多个子类被放置在容器中时,如果容器本身声明为基类,那么在插入容器进行拷贝的时候,会导致派生类部分的成员变量被切掉。因此在涉及到继承场景时使用容器,需要使用智能指针。
4.2 模版&范型编程
面向对象编程(OOP)和泛型编程都能处理在编写程序时不知道类型的情况。不同之处在于:OOP 能处理类型在程序运行之前都未知的情况;而在泛型编程中,在编译时就能获知类型。
类模版
// 模版type 可支持默认函数实参
template <typename T, typename U = int>
class Pair {
T first;
U second;
public:
Pair(T a, U b) {
first = a;
second = b;
}
T getFirst() {
return first;
}
U getSecond() {
return second;
}
};
函数模版
跟 Swift 等语言中的模版类似, 通过 compile time 进行拼装生成对应的函数.
template <typename T>
T add(T a, T b) {
return a + b;
}
成员模版
一个类(无论是普通类还是类模板) 可以包含本身是模板的成员函数。这种成员被称为成员模板(member template)。成员模板不能是虚函数。 这里继续用类模版中的例子。
template <typename T, typename U>
class Pair {
T first;
U second;
public:
// ....
// 成员模版 ~
template <typename V>
void modifyFirst(V value) {
first = value;
}
};
控制实例化
模板的实例化是指在编译时根据模板定义创建特定类型或值的代码的过程, 当模版被使用时才会实例化。因此可以通过 extern 关键字来避免在各个文件内部同时创建大量相同的模版实例导致开销。extern 可用于告诉编译模版实例化定义位于其他地方,且不需要在当前文件中进行实例化:
// mytemplate.hpp
template <typename T>
T add(T a, T b) {
return a + b;
}
// main.cpp
#include <iostream>
// 声明模板实例化定义位于其他文件中
extern template int add(int a, int b);
int main() {
int result = add(5, 10);
std::cout << "Result: " << result << std::endl;
return 0;
}
理解 std::move
std::move是 C++标准库中的一个函数模板,定义在头文件 <utility> 中。
它的定义如下:
template <typename T>
typename std::remove_reference<T>::type&& move(T&& t) noexcept {
return static_cast<typename std::remove_reference<T>::type&&>(t);
}
让我们逐步解释这个定义:
std::move是一个函数模板,接受一个参数t,类型为T&&。注意,这里使用了右值引用的类型(T&&),这是用来传递右值(例如临时对象和将要销毁的对象)的一种特殊引用类型。- 在模板函数内部,使用了
[std::remove_reference](https://en.cppreference.com/w/cpp/types/remove_reference)<T>::type来获取T的实际类型,去除了可能存在的引用。例如,如果T是int&,那么typename std::remove_reference<T>::type将会是int。 move()函数使用static_cast将参数t转换为右值引用T&&。这样,函数返回的就是一个右值引用。noexcept关键字表示该函数是不抛出异常的
重载与模版
函数模版可以被另一个模版或一个普通非模版函数重载。与往常一样,名字相同的函数必须具有不同数量或者类型的参数。
完美转发
完美转发的主要用途是在编写泛型代码时,能够在不改变参数的值类别(左值或右值)和 cv-qualifier(const 或 volatile)的情况下,将参数传递给其他函数。完美转发通常通过使用右值引用和 std::forward 来实现。例如:
template <typename T>
void wrapper(T&& arg) {
some_function(std::forward<T>(arg)); // Perfectly forward arg to some_function
}
完美转发带来了以下益处:
- 性能优化:完美转发可以避免不必要的拷贝,特别是在构造函数和赋值运算符中,这可以提高代码的性能。
- 资源安全:对于管理动态资源的类(如智能指针),完美转发可以确保资源的正确转移,避免资源泄露或重复删除。
- 通用编程:完美转发使得函数模板可以接受任意类型的参数,并将其转发给其他函数,而不改变参数的类型和值类别。这使得编写能处理任意类型参数的通用代码成为可能。
- 支持移动语义和右值:完美转发是实现移动构造函数和移动赋值运算符的关键,它们是 C++11 引入的用于优化性能的重要特性。
- 实现高级库和工具:许多高级库和工具(如 std::thread, std::bind 和 std::async)都依赖于完美转发来实现其功能。
可变参数与模版
可变参数模版支持两种参数包: 模版参数包, 表示零个或多个模版参数;函数参数包, 表示零个或多个函数参数。🌰 如下:
#include <iostream>
// 递归终止条件:当没有剩余参数时打印换行符并返回
void print() {
std::cout << std::endl;
}
// 打印第一个参数,然后递归调用print函数处理剩余参数
template<typename T, typename... Args>
void print(const T& first, const Args&... args) {
std::cout << first << " ";
print(args...);
}
int main() {
print(1, 2, 3); // 打印:1 2 3
print("Hello", 4, 5.6, "World"); // 打印:Hello 4 5.6 World
return 0;
}